




2024年实时数据爬取方法与策略

摘要:,,本文介绍了在大数据时代,如何有效地在2024年12月27日爬取实时数据。文章详细阐述了准备工作、具体步骤和注意事项,包括确定目标数据源、选择合适的爬虫工具、遵守相关法律法规等。具体步骤包括网页分析、请求设置、数据抓取、数据处理与存储,以及保障实时性的措施。文章还强调了遵守Robots协议、防范反爬虫策略、关注数据质量、网络安全和合规性等方面的注意事项。通过实例说明实际操作中的具体应用。
随着互联网技术的快速发展,数据爬取已成为获取网络信息资源的重要手段,特别是在当今大数据时代,实时数据的获取对于各行各业具有重要意义,本文将介绍在2024年12月27日如何有效地爬取实时数据,包括准备工作、具体步骤和注意事项。
数据爬取前的准备工作
1、确定目标数据源:明确需要爬取实时数据的来源,如新闻网站、社交媒体平台等。
2、选择合适的爬虫工具:根据目标数据源的特点,选择适合的爬虫框架和工具,如Scrapy、BeautifulSoup等。
3、了解相关法律法规:在爬取数据前,需了解相关的法律法规,确保爬取行为合法合规。
实时数据爬取的具体步骤
1、网页分析:对目标网站进行网页分析,了解网页结构、数据加载方式等。
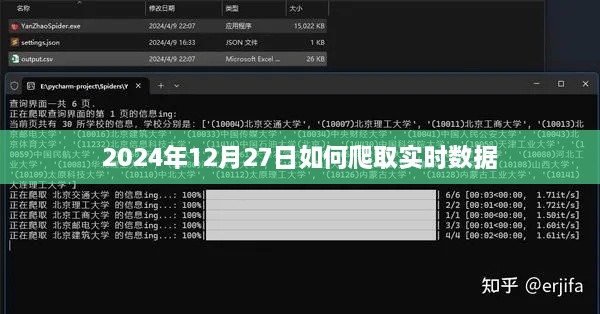
2、请求设置:根据网页分析的结果,设置合适的请求头、参数等,以模拟浏览器访问目标网站。
3、数据抓取:使用爬虫工具,从目标网站中抓取所需的数据。
4、数据处理与存储:对抓取到的数据进行清洗、整理,并存储在本地或数据库中,以便后续分析。
5、实时性保障:为确保数据的实时性,需定时更新爬虫,以适应目标网站的结构变化。
实时数据爬取的注意事项
1、遵守Robots协议:在爬取数据前,需遵守目标网站的Robots协议,确保爬取行为符合网站规定。
2、防范反爬虫策略:目标网站可能采取反爬虫策略,如验证码、限制访问频率等,需针对这些策略采取相应的应对措施。
3、数据质量:在爬取实时数据时,需关注数据质量,对抓取到的数据进行清洗和去重,确保数据的准确性和完整性。
4、网络安全:在爬取数据过程中,需关注网络安全问题,避免被黑客攻击或感染病毒。
5、合规性:在爬取实时数据时,需确保所抓取的数据不涉及版权、隐私等法律问题,遵守相关法律法规。
案例分析
以某新闻网站为例,介绍如何在2024年12月27日爬取其实时数据,通过网页分析了解该网站的数据加载方式;设置合适的请求头、参数等模拟浏览器访问;使用Scrapy框架抓取数据;对抓取到的数据进行清洗、整理并存储在数据库中,在爬取过程中,需关注数据质量、遵守Robots协议、防范反爬虫策略等。
本文介绍了2024年12月27日如何有效地爬取实时数据,包括准备工作、具体步骤和注意事项,在实际操作中,需根据目标数据源的特点选择合适的爬虫工具和方法,同时遵守相关法律法规,确保爬取行为的合法合规。
转载请注明来自江西北定建设工程有限公司官网首页,本文标题:《2024年实时数据爬取方法与策略》




 赣ICP备2021007627号-1
赣ICP备2021007627号-1
还没有评论,来说两句吧...